

When used effectively, new technological innovations can shape the way a business presents its customer experience. Part of that process involves gaining data from customer reviews, but utilizing Natural Language Processing (NLP) software can yield and elevate significant insights in a small amount of time. To help you navigate the landscape and get the most out of your NLP of choice, this educational resource will walk through the following areas:
- Why Natural Language Processing is Useful
- What to Look for in a Natural Language Processing System
- Natural Language Processing Across the Reputation Management Industry
Why Natural Language Processing is Useful
Reviews are invaluable for a business as a direct line to customer needs, but the sheer volume of reviews across multiple business review sites can be overwhelming. Customers feel empowered to voice their feelings and expect businesses to listen, while prospects rely on online reviews to guide their decision as to where to bring their business.
In fact, the reliance on reviews is so strong, with data showing an overwhelming 92% of consumers use online reviews to guide their ordinary purchase decisions. When it comes to managing the potential influx of reviews and Voice of the Customer data for any business, your organization has several options:
- Do nothing: The most hands-off approach is to not recognize it as a problem and do nothing. This may be due to not realizing the impact of reviews and reputation management or lacking the resources to gain insight from so many reviews.
- Dedicate Manpower: An alternative approach is the brute-force technique of dedicating sheer manpower to reading through reviews to identify trends in customer feedback. This is only a possibility for companies with very few reviews that have the ability to allocate work hours to this task. These companies may be best served by first working to increase the number of reviews they receive to boost their online presence. However, as soon as the number of reviews rises, the time and effort they spend will rise proportionally.
Other solutions to this dilemma use Natural Language Processing to automate parts of this analysis. Using advanced machine learning techniques, these models can read through thousands of reviews in the time it would take a human to read through just a few.
The right NLP technology will provide valuable summaries, trends and statistics that can be applied to support data-driven decision-making and business innovations.
One real-world example is a business that noticed a negative trend in their location category. Diving deeper, they found the system extracting the negative keyword smelly. This led the user to a number of reviews mentioning a dumpster near the entrance. With this realization, the business was able to take the simple action of relocating the dumpster to the back of the building, resolving this recurring customer annoyance.
What Kind of NLP Solutions are Available?
- Build your own model: The most customizable approach is to create your own in-house machine learning model. This is somewhat unrealistic, except perhaps for the largest of companies, because it requires a dedicated team of software engineers and data scientists to build and maintain.
- Use a generic solution: Another approach is a generic out-of-the-box solution, such as those offered by Amazon (as AWS Comprehend) or IBM (as Watson). These are structured to be easy to use even without programming skills. However, such models are not built specifically for online reviews, so the results will not perform as well as more tailored approaches. When considering which solution is right for you, it’s important to know what to look for in a system. Read the next section for more details on how to identify what makes a model appropriate for online reviews..
- Use a solution designed for reviews: A more balanced approach for most use cases is to work with a company that offers a product that leverages advanced machine learning technology and is specifically tailored to online reviews.
Through the use of a solution designed for review analysis, a 150+ location quick service restaurant (QSR) brand in the hospitality industry went from a 3.6 average rating to a 4.1 average rating in a matter of 6 months by improving business operations and identifying the specific need for specialized training courses for staff. This led to a 7% increase in revenue for their business.
Takeaway
NLP models for processing online reviews save a business time and even budget by reading through every review and discovering patterns and insights. This data can be applied to understand customer needs and lead to operational strategies to improve the customer experience.

What to Look for in a Natural Language Processing System
When it comes to analyzing review data, Natural Language Processing involves three core tasks: keyword extraction, sentiment analysis, and classification. This section will empower the reader to understand applications of these core tasks and how they can be applied suit specific needs. To further aid in these explanations, we will use example reviews and sample questions where possible.
Do your models use deep learning?
Artificial intelligence is a broad field, and terminology can quickly become confusing. One way to conceptualize the hierarchy of technology and terms is that AI is the broadest term, whereas machine learning is just one type of AI and deep learning is a further subset of machine learning.
Deep learning-based approaches achieve state-of-the-art results in the three core tasks mentioned at the beginning of this section. It may sound sleek to hear a software described as “using AI”, but be aware that that is a somewhat open-ended term that can potentially encompass simplistic, outdated, or poor-performing technologies. If you come across this terminology, it would be worth digging deeper to learn what type of AI approach is being used.
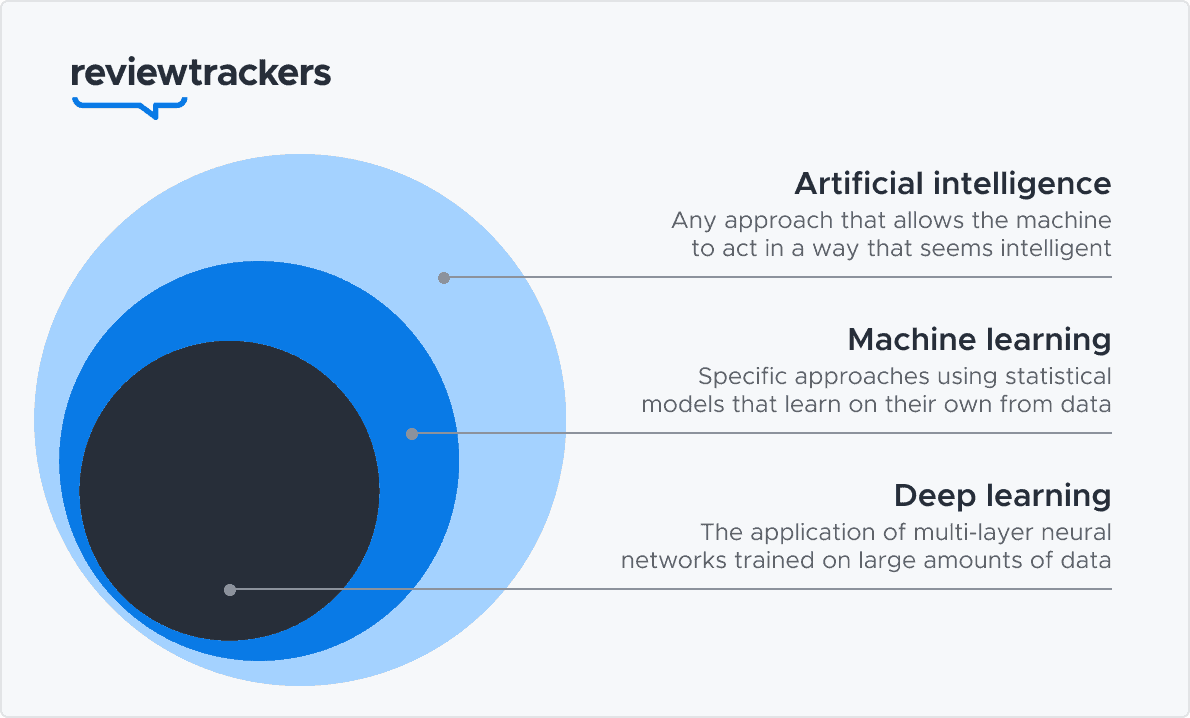
AI is the broadest term of the three; whereas machine learning is one type of AI and deep learning is a further subset of machine learning.
Are your models trained on in-domain data?
A key element of deep learning is that the computer model learns to perform the task by looking at example data. The quality of training data has a large impact on model performance. Data scientists sometimes describe this as “garbage in, garbage out”. That is to say, even an advanced model will not give good results if it is not trained on relevant, high-quality data.
For example, a huge tech company may train a state of the art model on massive amounts of data, such as all of Wikipedia plus millions of scraped Google webpages. This is undeniably a good starting point. However, if the final task is something more specific, such as extracting keywords from healthcare reviews, it helps to have training data that is more fine-tuned to the domain of the user’s end task.
Finally, one benefit of deep learning is that as better data comes in, the model can be retrained and learn from its past mistakes. It is unrealistic to expect perfect accuracy from any machine learning model, but it is good to check whether the user can flag errors, which are fed back to the base model so that over time, it learns to correct them.
Takeaway
Deep learning models achieve state-of-the-art performance. These models depend on the data they are trained on, so they should ideally be built using the same kind of data the end user plans to provide, such as online review data.

Keyword Extraction
Keyword extraction is a task that consists of extracting relevant terms from the review text. The definition of what constitutes a relevant term can vary wildly based on the data type and user needs. For example, over a corpus of news text, it is common to extract person, business, and location names. For review text, this can be much broader. Let’s look at the example review below. It is taken from the restaurant domain, but the same concepts apply to reviews in other domains, such as retail or healthcare:
“The waiter forgot our drinks at first, but they were worth the wait. So unique and tasty!”
Does the system extract adjectives and other parts of speech?
Initially, extracting only nouns may sound sufficient, but human language is wonderfully diverse and messy, so in practice many relevant pieces of information surface as different parts of speech. The simple approach of extracting only important nouns would only capture waiter, drinks, and possibly wait from our example above. Most analyses would benefit from capturing additional terms.
The example above contains the adjectives unique and tasty and the verb forgot. It is not a stretch to imagine other reviews that contain important adverbs such as quickly or professionally.
Does the system extract multi-word expressions?
The example review contains the phrase worth the wait. Consider other set phrases like on top of things or one of a kind. Systems that only extract single word nouns reduce those phrases to just things and kind, separating them from all of their informative impact.
Takeaway
The informed user of a Natural Language Processing system should be aware of what types of keywords that system can or cannot extract, and decide what level of coverage is optimal for their needs.

Sentiment Analysis
Sentiment analysis is another Natural Language Processing task, which assigns a sentiment prediction to a word or piece of text. When applied to reviews, this in effect analyzes whether the writer of the review is pleased or not with the topics they are writing about. Some research directions explore predicting more specific emotional qualities, such as angry, fearful, happy, sad, etc., but the overwhelming majority of systems use either a binary positive vs. negative sentiment, or sometimes include a neutral sentiment option in between. Again, an example review will be used to highlight different approaches to this task.

Does the system mark sentiment at the individual keyword level?
A major factor in sentiment analysis systems lies in the granularity of its predictions. Generally, a more fine-grained system is harder to build from a technical standpoint, but is more useful to the end user. At one extreme, one can imagine a system that simply marks the entire review as either positive or negative. For the example review, this could mean the entire review is marked as positive:

For very short reviews, this approach may be effective, but it is insufficient for all reviews that mention both good and bad attributes. As seen with the example review above, marking the entire review this way does not meaningfully capture the whole picture.
The next step down is to predict sentiment for each sentence in the review. However, as the example review shows, it is not uncommon for sentiment to be mixed within a single sentence. Some systems will simply return the sentiment label “neutral” or “mixed”, but this is not informative unless it tells you what specifically was positive and what was negative:

Can the system meaningfully handle two different sentiments in the same sentence?
A more advanced strategy is to use Natural Language Processing tools to extract a chunk of the sentence, usually a keyword and its immediately surrounding context. This way, the model can separate the positive chunk and the negative chunk from a mixed sentence and run prediction on each chunk separately. This performs well under ideal conditions, but due to the diversity and complexity of language use, it fails for many real world cases. In our example sentence, we know that the sentiment for burger should be positive because the reviewer loved it. However, because those words occur in separate sentences, it will likely be missed by this approach.

Finally, the most fine-grained approach is to directly mark each keyword for sentiment. This can be difficult to achieve, because the model needs to see the entire text of the review to look for clues whether the sentiment is positive or negative, but at the same time it needs to know which keyword to focus on for prediction. It would need to know that loved indicates positive sentiment for burger, but that it does not affect the prediction for the word service, despite being in the same sentence. Assuming the model is smart enough to overcome these hurdles, this is by far the most useful level of analysis for the end user.

Takeaway
Review-level sentiment analysis forces complex, nuanced, or longer statements into a single box, throwing away finer sentiment details. Sentiment analysis is most informative and useful when it can make a separate prediction over every keyword.

Classification
Classification refers to the task of assigning a word or piece of text to a class belonging to a pre-defined group. This is also sometimes called categorization, although it is not the same task as clustering. In many ways, classification parallels the task of sentiment analysis, except instead of the classes being positive and negative, they may be things like product, service, value, location, etc. Like sentiment analysis, the main consideration in classification is granularity. For more details on that, refer to the previous section. We can use the same example review from that section:

Can the system meaningfully handle multiple different classes in the same sentence?
The simplest approach is to assign the class label to the entire review. Some models assign only a single label, while multi-label classification is able to assign more than one.
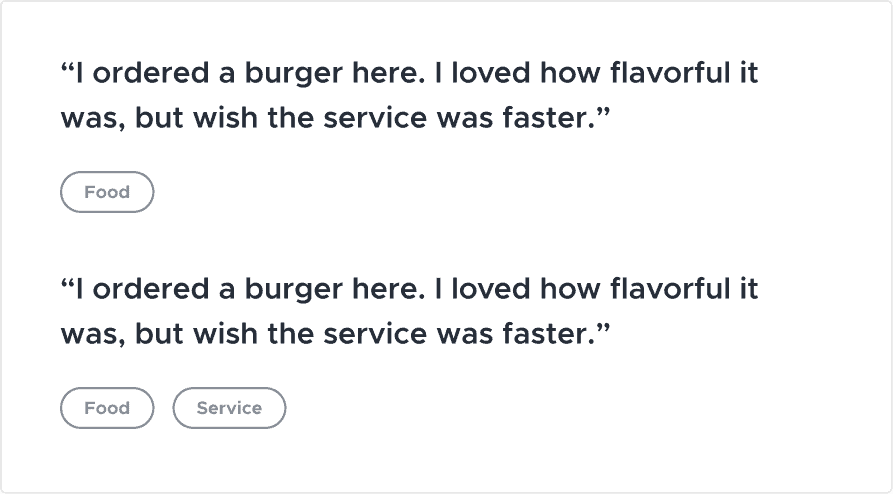
Using the example review, the single label approach might only assign it the label food. Because the review contains multiple labels, this fails to capture a lot of information. The multi-label approach would ideally assign the review to the food and service category. This is an improvement, but it still does not specify which parts of the review point to these classes.
Does the system predict class at the individual keyword level?
The most fine-grained approach to classification is keyword-level classification. Because most keywords only logically belong to a single class, multi-label classification is usually not relevant for this granularity.

The benefits of this approach compound over many reviews by allowing the user to select a certain category and see the exact breakdown of which keywords are driving the category.
Are the system’s classes relevant to the user?
So far, we have assumed that the classes food and service exist in the system, but it is best to verify that assumption. A more generic model may have classes that do not meaningfully align with online reviews or your business, such as ‘financial news’ or ‘operating system’. In this case, even a very advanced classification model will not be very informative on your data.
Does the system work without the user needing to define the classes?
All of these approaches described so far have assumed that an underlying machine learning-based model is doing the heavy lifting. However, other approaches are much more hands-off. Some systems require the user themself to define the category and create a list of keywords that belong to it. This approach has some large pros and cons.
- Pros: High level of customizability
- Cons: Time commitment from user, difficult to ensure coverage, lacks context awareness
The first con is that this requires a considerable time commitment from the user to define all their classes, whereas one of the main benefits of using machine learning and Natural Language Processing is to save time for the user.
The second is the recurring fact that language is complex and changing. Therefore, even with considerable effort, it is difficult to manually create an exhaustive list of all the keywords that should belong to a certain category. For example, even if a restaurant manually defines a food category and adds the terms burger, cheeseburger, and hamburger, a few months later customers may start mentioning the impossiburger. This will slip between the cracks of a hand-defined model.
Additionally, advanced deep learning models are able to leverage context to determine whether the keyword cold is referring to the food, location, or service, like this the following example:

In light of the above cons, the user-defined approach to classification is only suitable when the user needs very constrained and specific classes and has enough resources to devote the time needed to build them.
Takeaway
User-defined classification is time-intensive to set up and has poor coverage. Among deep learning-based models, keyword-level classification provides the most information.
Natural Language Processing Across the Reputation Management Industry
Below we present a chart covering some of the questions presented in the previous sections and how various Natural Language Processing services handle them. This chart is a good-faith summarization of the field based on the available resources at the time of writing. Please keep in mind that these features may change over time, so it is best to verify whether the latest version of a certain service can or cannot handle any given task.
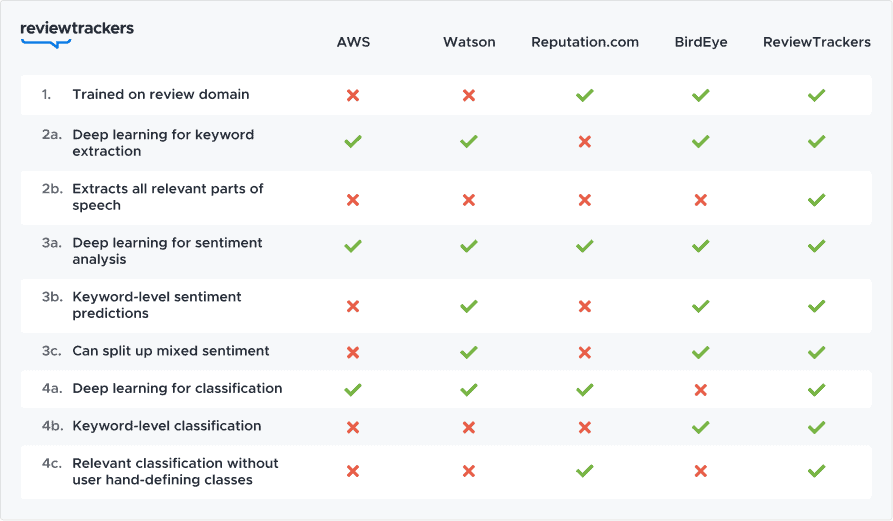
To further provide context on the data above, we made the following notes on the data gathered:
(1) This graph assumes the out-of-the-box model. AWS and Watson do allow a user to provide annotated data to further fine-tune their model, but that requires time and effort to collect and label the data.
(2a/b) AWS and Watson generally only extract nouns. Reputation.com does not seem to extract any keywords at all for sentiment analysis or classification. BirdEye extracts some but not all relevant adjectives, and misses other parts of speech.
(3a/b/c) All services offer some form of sentiment analysis, but AWS and Reputation.com perform this only at the sentence-level.
(4a/b/c) AWS and Watson do have deep learning-based classification models, but they use generic classes (e.g. Politics, Operating Systems, Financial News) that are not specifically relevant to the review domain. Because BirdEye does not have a deep learning-based classification model, the user has to manually define their own classes and populate which keywords belong to that class.
Model Accuracy
This chart covers the high-level approach to these tasks, but does not address the accuracy of the models. For example, even between two services that perform keyword-level sentiment analysis, one may predict the incorrect sentiment more frequently than the other. Accuracy is more difficult to rigorously compare without a standardized test dataset and full access to each service. The user is encouraged to try running several of the same reviews between competing services to get a feel for their accuracy levels. One easy approach is to use the example reviews given in Section 2 of this paper, as they contain features where many systems fall short.
Model Architecture
Besides quality training data, the largest factor in model performance is the type of deep learning architecture it uses. A revolution occurred recently in the field of Natural Language Processing with the introduction of “BERT” (Bi-directional Encoder Representations from Transformers), developed by the Google AI team. This model was able to achieve state of the art performance on multiple NLP tasks. On a common performance benchmark, models derived from BERT actually beat the human baseline on several tasks. Google even introduced BERT into their own search algorithm. ReviewTrackers is proud to use models such as BERT and its derivatives to stay at the cutting-edge of the field.
Takeaway
ReviewTrackers focuses on developing and maintaining its three core Natural Language Processing strengths: covering all of the key areas shown in the chart; focusing specifically on reviews with custom-built, in-house, in-domain models trained on actual review data; and using the latest NLP technology to push accuracy higher and uncover new insights.
In Conclusion
Online reviews provide a wealth of insights for a business, but can be labor-intensive to read through and digest. There are many ways to try to automate this task. Currently, the leading approaches use deep learning models trained on online review data. The models best suited to this application are able to extract many different kinds of keywords, predict their sentiment, and classify them into relevant categories, which allows businesses to improve operations, make better decisions and elevate the customer experience with data.
Learn More About ReviewTrackers’ NLP, Data Insights and Customer Analytics
To learn more about this amazing technology and how it can help you upgrade your customer’s experiences, visit this page.